
You launch a new ad set with five creatives. Within 48 hours, one of them is taking 80% of the spend, while the others barely move past a few hundred impressions.
Nothing is technically broken. But the test you thought you were running is no longer happening.
What This Looks Like Inside Ads Manager
The shift usually happens fast.
At first, delivery appears balanced. Then it collapses. One ad starts pulling the majority of impressions — often 70–95% of total spend within a few days — while the rest stall.
A few consistent signals show up:
-
One ad dominates spend;
the rest receive too little delivery to generate reliable data. -
Most creatives remain in learning;
they never accumulate enough events to exit it, so they stay suppressed. -
Early performance looks strong;
but conversion quality drops as delivery expands.
What matters here is not just the imbalance, but the consequence. Once most ads fail to gather data, your test is effectively over — even if all creatives are still active.
This pattern closely mirrors what’s explained in Why Facebook Ads Performance Declines Over Time (and How to Prevent It). Early signals create a false sense of stability that breaks as soon as the system expands delivery.
Why Spend Collapses Into One Ad
The system is not trying to test ads evenly. It is trying to reduce uncertainty in each auction.
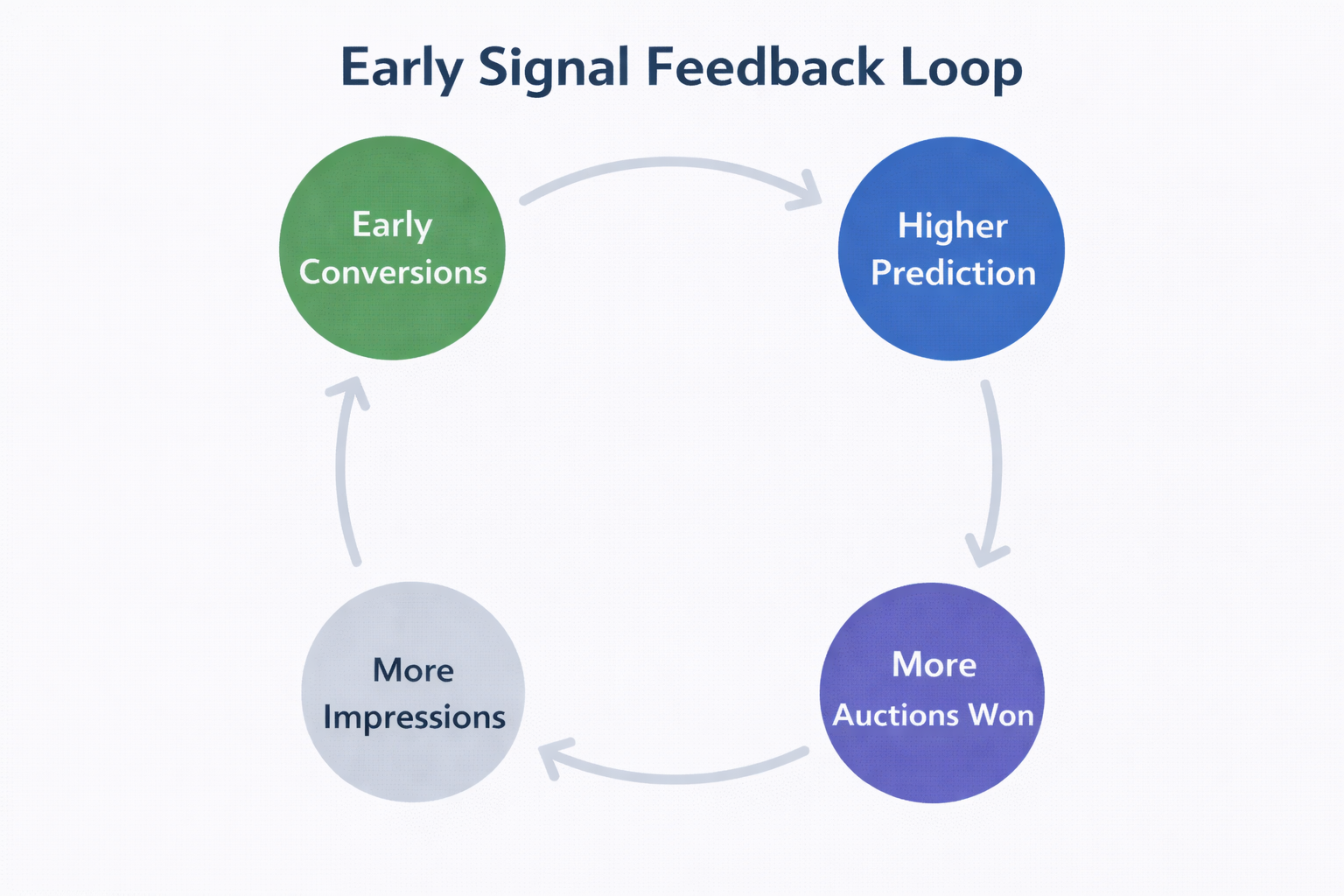
When an ad generates early conversions, the system treats that as a reliable pattern. It clusters those users and starts prioritizing similar ones. From there, a feedback loop forms:
-
the ad wins more auctions;
-
gains more impressions;
-
generates more conversions;
-
and strengthens its predicted performance.
The key issue is how early this loop starts. These signals often come from a very narrow audience slice, but the system treats them as broadly valid.
This behavior comes directly from how Meta’s auction works — explained in detail in Crack the Code: What You Need to Know About the Facebook Ad Auction. The system doesn’t wait for certainty; it acts on probability.
Small Differences Turn Into Big Outcomes
The system doesn’t need a clear winner. It just needs a slightly safer bet.
Even a small difference in predicted performance leads to:
-
more auction wins for one ad;
-
less delivery for others;
-
and a widening performance gap.
Over time, this compounds into near-total spend concentration.
This is why many advertisers misinterpret results. What looks like a strong winner is often just the first ad that gained enough early traction to trigger scaling.
Why the System Stops Exploring
This is where most advertisers misread what’s happening.
The system is not failing to test. It is actively avoiding uncertainty.
You’ll typically notice:
-
Spend concentrates within 24–72 hours;
-
new ads struggle to gain impressions;
-
performance stabilizes before enough data exists.
At that point, exploration is effectively over.
What this means in practice is simple: the system would rather commit to a decent option than risk testing unknown ones. That’s also why campaigns get stuck in limited delivery states, as explained in What Does “Learning Limited” Mean in Facebook Ads?
When Creatives Are Too Similar, Testing Breaks
If your ads are too similar, the system doesn’t treat them as distinct inputs.
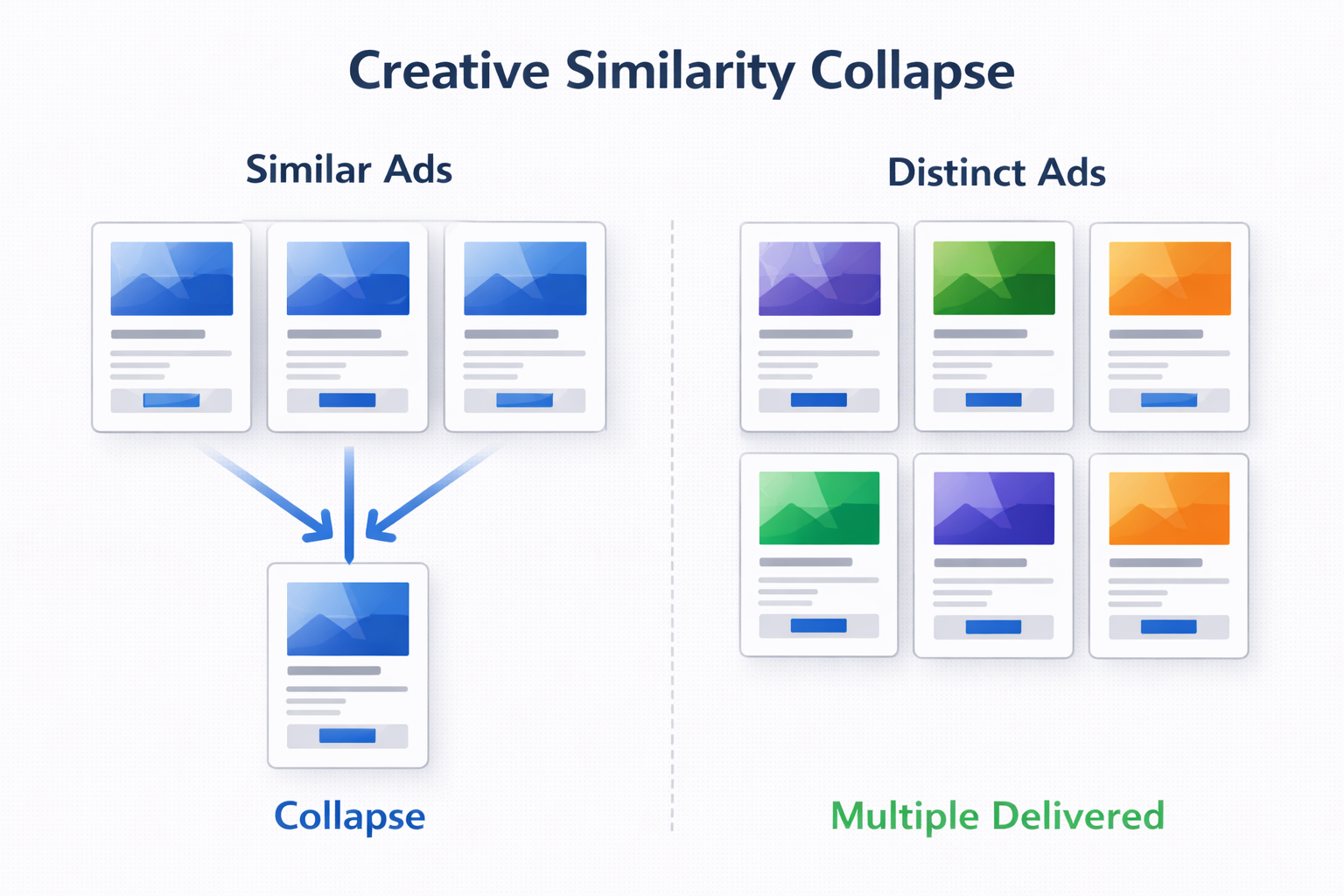
That usually happens when:
-
the message stays within the same angle;
-
visual structure doesn’t meaningfully change;
-
engagement behavior looks identical across ads.
In that case, one ad becomes the default, and the rest are ignored.
The important point here is that variation alone is not enough. If differences don’t change user behavior, they don’t create new signals. This is exactly the issue described in Creative Clutter: How Too Many Variations Hurt Facebook Ad Performance.
Why This Becomes a Performance Problem
At a glance, this looks efficient. One ad performs, so the system scales it.
But structurally, it creates blind spots:
-
You lose visibility — other creatives never get evaluated properly;
-
You misidentify winners — early results reflect conditions, not long-term performance;
-
You accelerate fatigue — one ad absorbs all exposure, increasing frequency faster.
The issue is not just missed insights. It’s that decisions based on incomplete data tend to compound over time, making later optimization harder.
How to Regain Control
You don’t need to force equal spend. You need to shape how the system learns.
Three adjustments make the biggest difference:
-
Separate fundamentally different ideas;
if ads represent different strategies, isolate them in different ad sets. -
Create real differentiation;
not small edits, but changes in message, structure, or intent. -
Control the first 48 hours;
high budgets early will lock in weak signals faster, reducing exploration.
These changes work because they don’t fight the algorithm — they change the conditions under which it makes decisions.
When It’s Actually Fine
Spend concentration is not always a problem.
It’s acceptable when:
-
the campaign is past testing;
-
performance remains stable across time;
-
frequency is under control;
-
results hold during scaling.
In this case, the system is doing what it’s supposed to do — scaling something that has already proven reliable.
Practical Takeaway
When one ad gets all the spend, the system isn’t picking a winner.
It’s committing early to reduce uncertainty.
If your structure doesn’t allow multiple ads to generate meaningful signals, the outcome is predictable:
-
one ad dominates,
-
others disappear,
-
and your test becomes invalid.
To fix it, focus on:
-
early signal quality,
-
real creative differentiation,
-
and controlled testing conditions.
That’s what turns ad delivery into something you can actually test, interpret, and trust.
