
Many teams run “tests,” but few follow a process. Common pitfalls include:
-
Testing too many variables at once
-
Changing setups mid‑test
-
Drawing conclusions from insufficient data
-
Failing to document results in a usable way
The result is fragmented learning and decisions based on intuition instead of evidence.
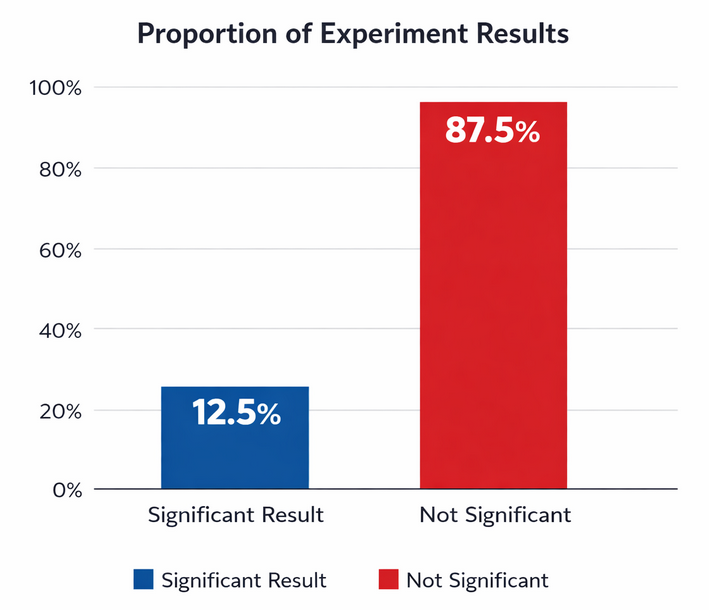
Proportion of experiments that yield statistically significant results vs. those that do not
According to industry benchmarks, over 60% of paid media experiments are inconclusive due to poor test structure or insufficient sample size. A repeatable system eliminates this waste.
What Makes a Testing Process Repeatable
A repeatable testing process has four defining characteristics:
-
Clear hypotheses – every test answers a specific question
-
Controlled variables – only one meaningful change per test
-
Defined success metrics – decided before launch
-
Standardized documentation – results are easy to compare over time
Without these elements, tests cannot be reliably reproduced or scaled.
Step 1: Define the Hypothesis
Every test should start with a single, falsifiable statement:
“If we change X, we expect Y because Z.”
Examples:
-
If we narrow audience similarity, cost per conversion will decrease because relevance increases.
-
If we segment creatives by intent level, click‑through rate will improve due to message alignment.
Tests without hypotheses tend to generate data, not insight.
Step 2: Isolate One Variable
To maintain clarity, test one variable at a time:
-
Audience structure
-
Creative format
-
Messaging angle
-
Placement or delivery optimization
Data from large‑scale ad accounts shows that single‑variable tests produce ~35% clearer performance signals compared to multi‑change experiments, which often mask the true driver of results.
Step 3: Set Minimum Data Requirements
Decide your stopping rules before launching:
-
Minimum spend per variant
-
Minimum number of conversions
-
Minimum test duration (typically 5–7 days)
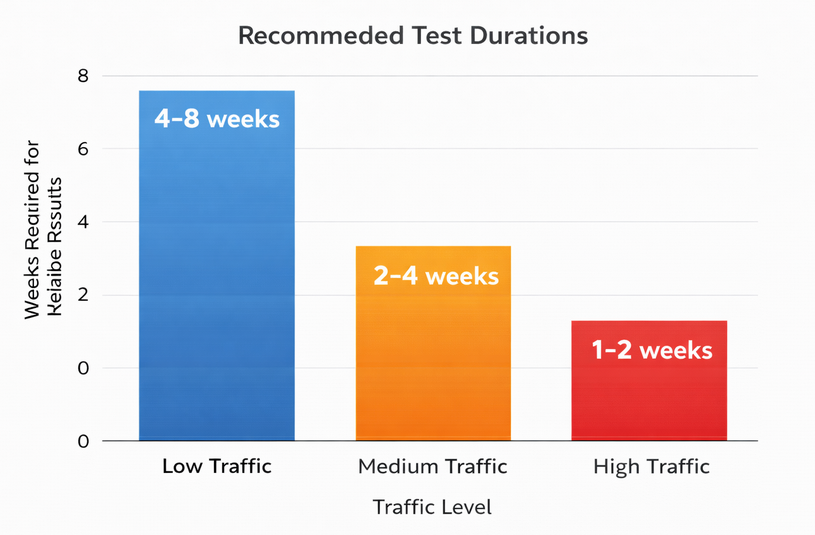
Recommended minimum test durations by site traffic volume to achieve reliable results
Statistical best practices suggest that tests reaching at least 100 conversion events per variant are significantly more reliable than those stopped early.
Stopping too soon creates false positives—and false confidence.
Step 4: Standardize Metrics and Evaluation
Choose a small, consistent set of core metrics:
-
Cost per conversion
-
Conversion rate
-
Click‑through rate
-
Return on ad spend (if applicable)
Avoid changing the “winner” definition mid‑test. Historical data shows that teams who pre‑define success criteria are 2× more likely to scale profitable variations than teams who evaluate subjectively.
Step 5: Document and Systemize Learnings
A test that isn’t documented might as well not exist.
Create a shared testing log that includes:
-
Hypothesis
-
Setup details
-
Budget and duration
-
Results vs. control
-
Key takeaway
-
Next test informed by this result
Over time, this builds a proprietary performance dataset—your most defensible growth asset.
Step 6: Turn Winning Tests Into Templates
Repeatability comes from turning results into rules:
-
Proven audience structures
-
Messaging frameworks by funnel stage
-
Creative patterns that consistently outperform
Accounts that operationalize learnings into templates see 20–30% faster optimization cycles compared to those starting from scratch each time.
Common Mistakes to Avoid
-
Declaring winners based on CTR alone
-
Restarting tests after partial data loss
-
Ignoring negative results
-
Treating every test as “unique”
Negative tests are not failures—they are filters that prevent future waste.
Build for Compounding Results
A repeatable testing process shifts optimization from reactive to systematic. Instead of chasing the next idea, you refine a framework that compounds over time.
The goal is not more tests—it’s better decisions per test.
Recommended Reading
To deepen your testing framework, explore these related articles:
Each expands on key elements of building systems that outperform intuition.
