
Lookalike audiences are often treated as a reliable scaling tool. When the seed audience is strong, the platform can model behavioral patterns and extend them to new users who resemble your converters.
The problem appears when the seed audience itself contains weak signals.
If the input data is noisy, sparse, or structurally biased, the lookalike model does not expand high-quality patterns. It simply replicates the flaws embedded in the source audience. This is why some lookalike campaigns scale efficiently while others produce large volumes of low-intent traffic.
Before building lookalikes, it is worth diagnosing whether the seed audience actually contains strong signals. The checks below help identify when a source audience is likely to produce unreliable expansion.
The approach follows the diagnostic style recommended in the LeadEnforce writing standard: explain the mechanism, understand the implication, and translate it into practical action.
Why Seed Quality Determines Lookalike Performance
Lookalike modeling works by identifying statistical similarities between people in your source audience. The algorithm examines behavioral signals such as engagement patterns, device usage, demographic attributes, and activity clusters.
It then searches the broader platform population for users who exhibit similar combinations of signals.
If the seed audience contains consistent behavioral patterns, the model can detect stable signals and extend them to new users. If the seed is inconsistent, the system struggles to identify meaningful patterns and falls back on broader correlations that rarely predict conversions.
This is why two lookalikes created from the same number of users can perform very differently.
A large seed audience does not automatically mean a good seed audience. Understanding the fundamentals of how these models work helps avoid this mistake, as explained in The Ultimate Guide to Facebook Lookalike Audiences.
The Most Common Causes of Weak Seed Audiences
Before diagnosing specific problems, it helps to understand what usually weakens a seed audience in the first place.
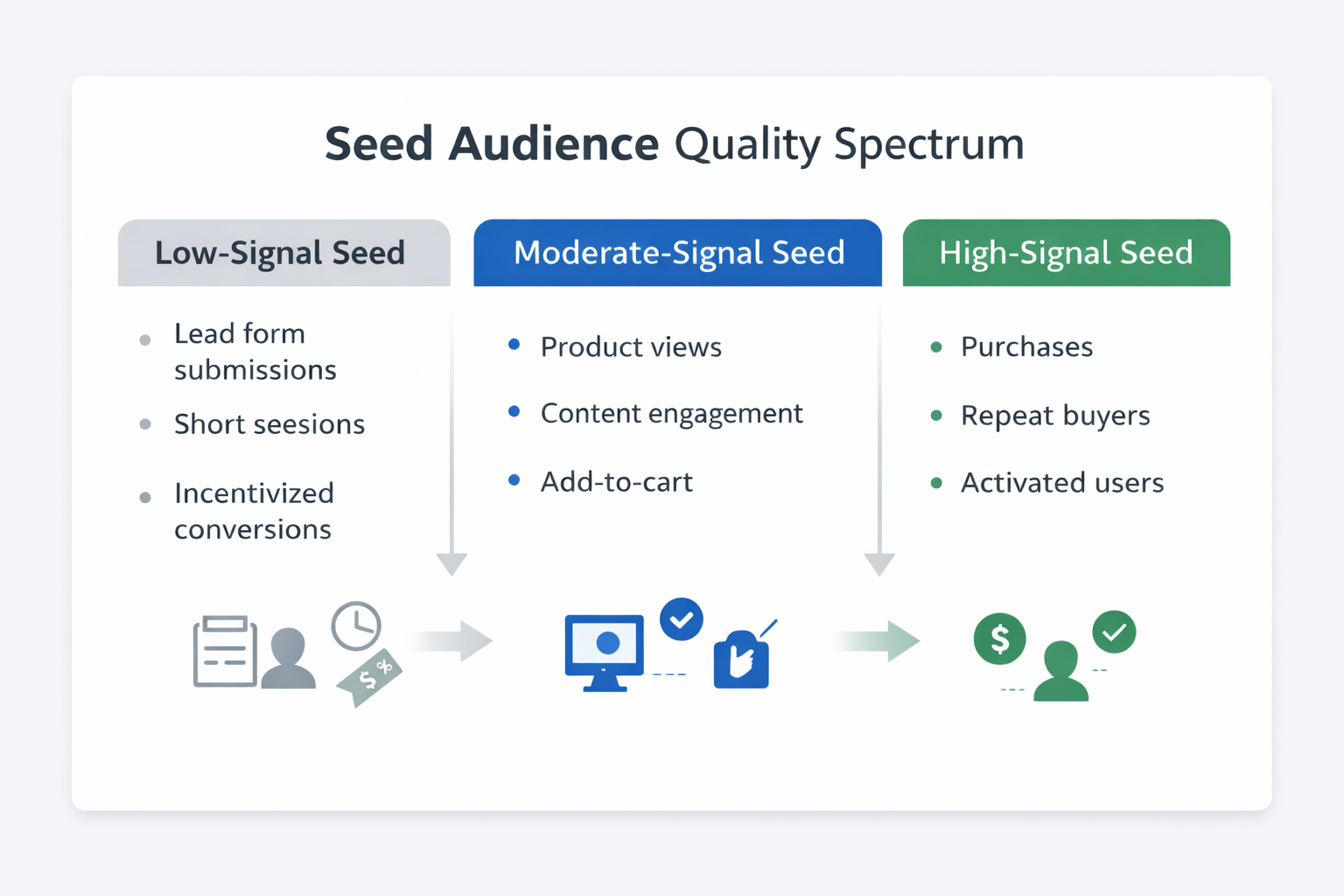
1. Mixed conversion intent
Many seed audiences include users who converted for very different reasons.
For example:
-
Trial signups driven by curiosity rather than product need.
These users may explore the product briefly but have little intention of adopting it long term. -
Incentivized conversions from discounts or limited offers.
Their behavior reflects the promotion rather than genuine demand. -
Low-commitment lead form submissions.
Some users fill forms impulsively and never follow through with meaningful engagement.
When these behaviors are combined in the same seed audience, the algorithm cannot distinguish between high-intent and low-intent converters. The resulting lookalike often expands toward the largest behavioral cluster rather than the most valuable one.
2. Sparse post-conversion behavior
Strong seed audiences contain users who continue interacting with your product or service after converting.
For example:
-
SaaS users who log in repeatedly during their first week.
-
Ecommerce buyers who return for additional purchases.
-
Leads who move deeper into the sales process.
When these signals are missing, the platform has fewer data points to define what makes a converter valuable.
The algorithm may then rely heavily on superficial characteristics such as demographic similarity rather than behavioral similarity.
3. Pixel attribution noise
Conversion tracking sometimes includes users who were not actually influenced by the campaign.
Typical scenarios include:
-
Users who discovered the product organically but happened to click an ad earlier.
-
Returning customers who convert again after seeing a remarketing impression.
-
Multi-touch journeys where the ad receives credit despite minimal influence.
These users become part of the seed audience even though their behavior does not represent your acquisition target.
Over time, this attribution noise can dilute the patterns that lookalike models attempt to replicate. Attribution issues like these are explored in more detail in Meta Ads Attribution: What to Know About Windows, Delays, and Data Accuracy.
Diagnostic Signals That Reveal Weak Seed Data
Once you understand the structural causes, the next step is identifying observable signals inside the ad account.
These indicators often appear before lookalike performance visibly deteriorates.
Rapid performance decay when scaling lookalikes
A common symptom is when lookalike audiences perform well at small budgets but degrade quickly as spending increases.
This usually indicates that the model captured only shallow similarities from the seed audience. The first small segment of users may resemble your converters superficially, but the signal cannot support broader expansion.
Strong seeds tend to produce stable performance across multiple scale levels. If scaling repeatedly breaks performance, it may also signal structural issues discussed in Why Your Lookalike Audiences Underperform (And What to Do About It).
Large variance between similar lookalike percentages
Another diagnostic clue appears when small percentage changes produce dramatic performance swings.
For example:
-
A 1% lookalike performs acceptably.
-
A 2% lookalike suddenly doubles CPA.
-
A 3% lookalike becomes almost unusable.
This pattern suggests the seed audience lacks consistent behavioral patterns. The algorithm quickly loses predictive accuracy as it expands beyond the narrowest similarity threshold.
High overlap between lookalike audiences
Weak seeds sometimes produce lookalikes that overlap heavily with each other.
Instead of representing distinct behavioral expansions, the audiences cluster around the same underlying group of users. This happens when the algorithm cannot identify clear differentiation signals in the source data.
Audience overlap tools often reveal this issue immediately. If you want a deeper explanation of how this problem affects campaign performance, see Why Audience Overlap Is Killing Your Facebook Ad Performance.
Practical Checks Before Building a Lookalike
Before launching a new lookalike audience, you can run several quick diagnostics on the seed dataset.
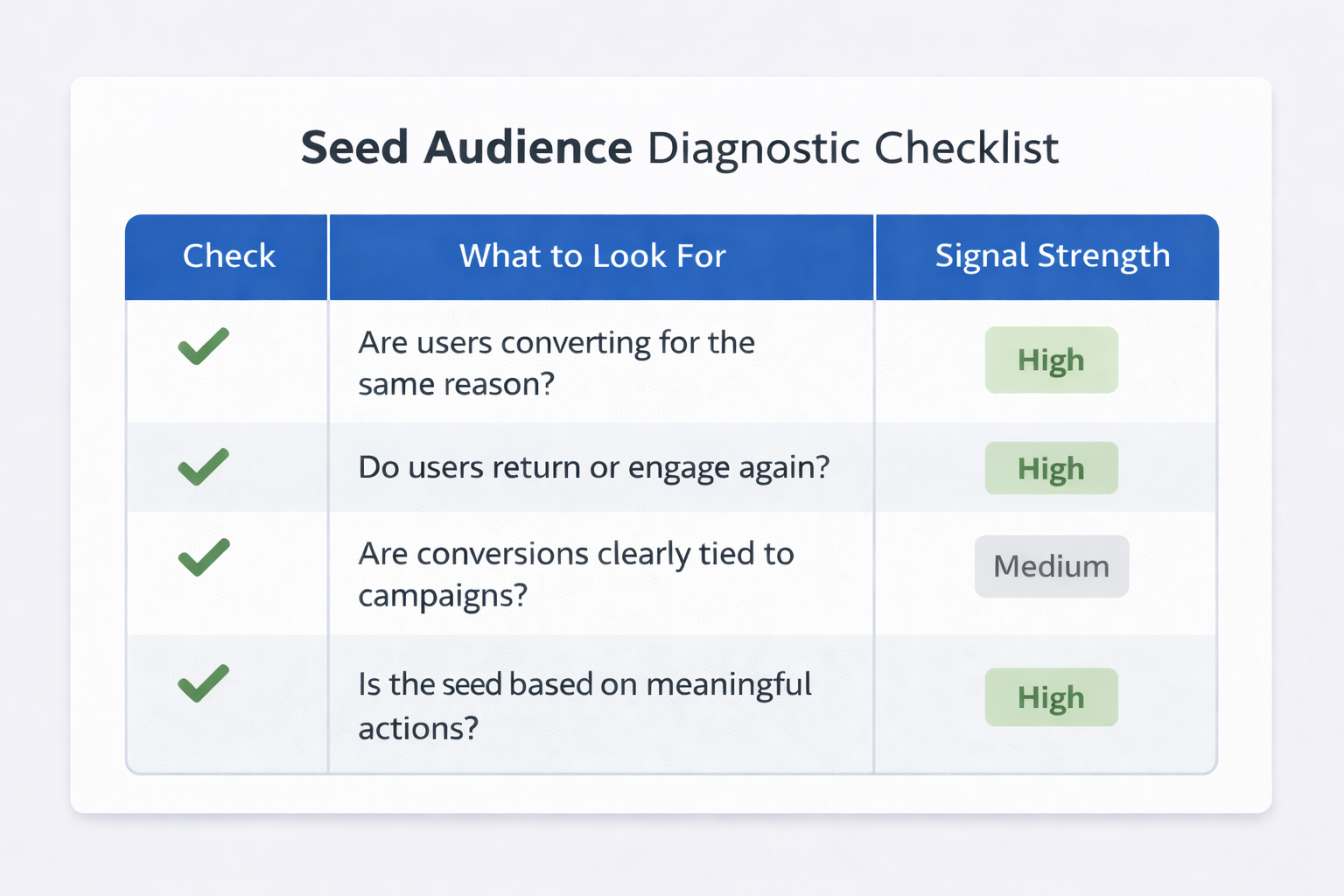
Check conversion consistency
Look at the behavioral profile of users inside the seed audience.
Ask questions such as:
-
Do most converters follow a similar path before converting?
For example, visiting several key pages or interacting with specific content. -
Do they show continued engagement after conversion?
Returning sessions, repeat product usage, or deeper funnel actions. -
Are conversions clustered around a specific audience segment?
Industry, location, or product use case.
When these patterns are consistent, the seed audience provides clearer modeling signals.
Segment high-intent converters
If your conversion pool contains mixed intent levels, isolate the strongest subset.
Examples include:
-
Users who completed onboarding or activation.
-
Customers who made a second purchase.
-
Leads who reached a sales-qualified stage.
Using this subset as the seed audience often produces a smaller but far more reliable lookalike model.
Analyze time-to-conversion
Another useful diagnostic is the time delay between first interaction and conversion.
Healthy seeds often show relatively predictable conversion windows. When the delay varies dramatically across users, it suggests multiple conversion motivations are mixed together.
This usually indicates that the seed audience needs segmentation before modeling.
Improving Seed Quality Before Scaling
If your diagnostics reveal weak seed signals, the solution is not simply increasing the audience size.
Instead, focus on improving the behavioral clarity of the source audience.
Several adjustments help strengthen the data:
-
Prioritize deeper funnel events.
Instead of building seeds from generic lead submissions, use events that represent meaningful engagement or commitment. -
Exclude ambiguous converters.
Remove users who converted through incentives, giveaways, or short-term promotions that distort behavior patterns. -
Use value-based segmentation when possible.
If your platform supports value signals, prioritize customers who generate higher revenue or retention. -
Allow the dataset to mature.
Building lookalikes too early often produces unstable results because the algorithm has limited behavioral data.
These steps reduce noise and give the platform clearer patterns to model.
A Simple Rule for Lookalike Reliability
The reliability of a lookalike audience depends less on the size of the seed and more on the clarity of the behavioral signal.
A smaller audience of highly consistent converters often produces better expansion than a large audience with mixed intent and attribution noise.
Before creating a lookalike, treat the seed audience as a dataset that requires validation.
If the source data reflects strong and consistent conversion behavior, the algorithm can scale that pattern. If the signals are weak or inconsistent, the model simply spreads those weaknesses across a larger audience.
Diagnosing seed quality early prevents wasted budget and makes lookalike scaling far more predictable.
