
Ad testing is supposed to bring clarity. Instead, many marketers end up with confusing results, wasted budgets, and no clear direction on what to scale. The problem is rarely the platform or the creative—it’s the way tests are designed, run, and interpreted.
Below are the most common reasons ad tests fail, supported by industry data, along with practical ways to fix them.
1. Testing Too Many Variables at Once
One of the fastest ways to ruin an ad test is changing multiple elements at the same time. When headlines, visuals, audiences, placements, and bidding strategies all vary in a single test, it becomes impossible to know what actually influenced performance.
According to marketing experimentation benchmarks, over 60% of failed ad tests are inconclusive because too many variables were introduced simultaneously. Without isolation, results become noise rather than insight.
How to fix it:
-
Test one primary variable per experiment (for example, creative or audience).
-
Keep all other elements identical.
-
Document each test so learnings compound over time.
2. Not Allowing Enough Data to Accumulate
Many tests are stopped too early. Performance fluctuations in the first few days are normal, especially in auction-based ad platforms that require learning periods.
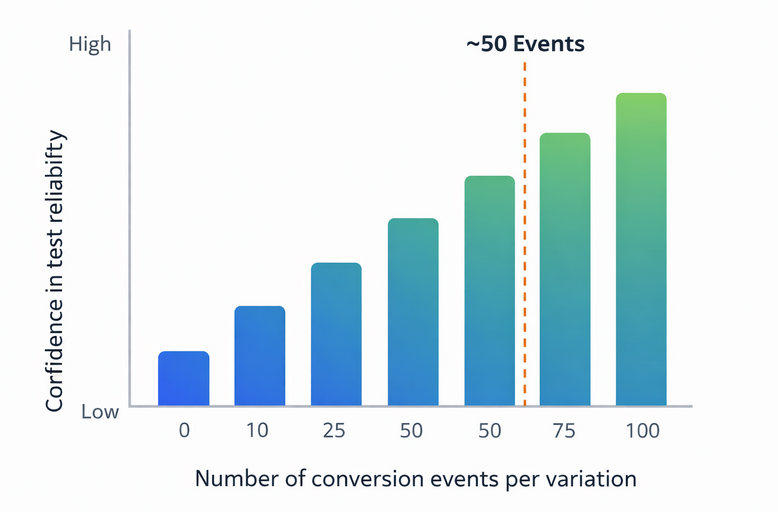
Conversion event volume and test reliability: reliability improves significantly once ~50 events are reached. Based on recommended ad testing practices
Industry data shows that ad platforms typically need at least 50 conversion events per variation to stabilize delivery and produce meaningful results. Tests that end before this threshold often favor short-term volatility rather than true performance.
How to fix it:
-
Define a minimum data requirement before launching the test.
-
Use conversions or statistically relevant events as the decision metric.
-
Resist the urge to judge performance within the first 24–72 hours.
3. Testing Without a Clear Hypothesis
Many ad tests begin with the question, “What happens if we try this?” rather than a clear hypothesis. This leads to random experimentation without strategic direction.
A structured testing approach can increase optimization efficiency by up to 30%, compared to ad hoc testing methods. Hypothesis-driven tests create faster learning cycles and more actionable outcomes.
How to fix it:
-
Write a clear hypothesis before launching each test (for example: “Shorter headlines will increase click-through rate by reducing cognitive load”).
-
Define success metrics in advance.
-
Evaluate results based on whether the hypothesis was validated or disproven.
4. Relying on Vanity Metrics
Click-through rate and impressions often look impressive but don’t always translate into business results. Optimizing for surface-level metrics can lead teams to scale ads that attract attention but fail to convert.

Comparison of typical ROAS outcomes when optimizing for click-through rate (CTR) versus conversion- or revenue-oriented metrics — illustrating why focusing on vanity metrics can underdeliver
Studies show that campaigns optimized solely for CTR can deliver up to 40% lower return on ad spend compared to campaigns optimized for conversion or revenue-based metrics.
How to fix it:
-
Align test metrics with business goals such as cost per acquisition or lifetime value.
-
Use secondary metrics (CTR, CPC) only for diagnostic insights.
-
Make scaling decisions based on profitability, not engagement alone.
5. Using Audiences That Are Too Broad or Too Small
Audience selection plays a major role in test accuracy. Broad audiences can dilute results, while overly narrow audiences may never reach statistical significance.
Research indicates that mid-sized, high-intent audiences often outperform both extremes, delivering more consistent cost per conversion and faster learning cycles.
How to fix it:
-
Ensure each audience is large enough to generate consistent conversions.
-
Avoid overlapping audiences within the same test.
-
Refresh or rotate audience segments regularly to prevent fatigue.
6. Ignoring Test Learnings After Completion
Perhaps the most overlooked failure is not applying insights once a test ends. Many teams run experiments, declare a winner, and move on without documenting or systemizing the learning.
Organizations that maintain a structured testing log improve campaign performance up to 25% faster than those that don’t, according to internal marketing operations studies.
How to fix it:
-
Record outcomes, hypotheses, and conclusions after every test.
-
Apply learnings across campaigns, not just the winning ad.
-
Build a repeatable testing framework rather than one-off experiments.
Turning Ad Testing Into a Growth System
Successful ad testing isn’t about running more experiments—it’s about running better ones. By isolating variables, waiting for sufficient data, focusing on meaningful metrics, and applying learnings systematically, testing becomes a predictable driver of performance rather than a guessing game.
When done correctly, structured testing can reduce acquisition costs, improve conversion rates, and create a clear roadmap for scaling campaigns with confidence.
