
Value-based lookalike audiences promise a more advanced way to scale Meta advertising. Instead of treating every purchase equally, the algorithm attempts to identify users who resemble your highest-value customers.
For large advertisers with thousands of conversions, this approach can work well. For small accounts, however, value-based lookalikes often produce unstable delivery and inconsistent results.
The problem usually isn’t the lookalike feature itself. The issue is that small datasets rarely contain enough reliable value signals for Meta’s modeling system to learn from.
To understand why this happens, it helps to examine how value-based lookalikes are built and what data conditions they require.
How Value-Based Lookalike Audiences Actually Work
A standard lookalike audience models behavioral similarity. Meta analyzes the users in a seed audience and searches for people across the platform who behave in similar ways.
Value-based lookalikes introduce another signal: purchase value weighting.
When you upload a seed audience that includes purchase values, Meta ranks users according to how much revenue they generated. Higher-value customers influence the model more strongly.
The modeling process generally follows several steps:
-
Seed events are ranked by purchase value.
Each conversion in the dataset includes a value parameter. Purchases with higher values receive stronger weighting in the training process. -
Behavioral attributes are extracted from the seed users.
Meta evaluates signals such as device usage, engagement patterns, browsing behavior, ad response history, and interaction with different content formats. -
Similarity scores are weighted by value.
Users who resemble higher-value buyers receive stronger similarity scores than users who resemble lower-value customers. -
The platform builds an expanded audience.
The system identifies new users across Meta properties who match the weighted behavioral profile of those high-value buyers.
This approach works best when the seed audience contains enough conversions to reveal meaningful value patterns.
Small accounts rarely meet that requirement.
If you need a broader explanation of how lookalike modeling works, the article The Ultimate Guide to Facebook Lookalike Audiences explains the underlying mechanics in more detail.
A Small Number of Purchases Can Distort the Model
Many smaller advertisers attempt value-based lookalikes with only a few dozen purchases.
A typical dataset might contain:
-
40–60 purchases in the seed list;
-
most orders between $40 and $80;
-
two or three purchases above $200.
Once value weighting enters the model, those few expensive orders become disproportionately influential.
The algorithm attempts to identify the behavioral attributes associated with those high-value buyers. In small datasets, those attributes may simply reflect coincidental patterns rather than real customer segments.
Situations like this occur frequently in smaller ecommerce accounts:
-
A customer places a bulk order during a seasonal promotion.
-
A repeat buyer purchases several products at once.
-
A one-time corporate order appears among consumer purchases.
The algorithm interprets these events as signals of high-value customer profiles. As a result, the lookalike audience becomes optimized for patterns that may occur only a handful of times.
Delivery then becomes unstable because the model is trying to replicate behavior that rarely exists at scale.
Limited Behavioral Diversity in Small Seeds
Another structural limitation appears in the composition of the seed audience itself.
Large advertisers usually feed the algorithm thousands of conversions originating from multiple campaign types, including:
-
prospecting campaigns bringing in new users;
-
retargeting campaigns converting engaged visitors;
-
repeat customers purchasing multiple product categories;
-
traffic from different acquisition channels.
This diversity allows Meta to identify reliable behavioral patterns across many different users.

Small accounts often have much narrower datasets. For example:
-
most conversions come from retargeting campaigns;
-
customers arrive through nearly identical funnels;
-
purchases occur after similar engagement sequences.
When the seed dataset lacks diversity, the model struggles to separate meaningful signals from random variation. Adding value weighting on top of that limited dataset can make the modeling process even more fragile.
For a deeper discussion of how seed quality affects modeling accuracy, see Lookalike Audiences: How to Seed, Train, and Scale.
Overfitting Becomes a Real Risk
Small value-weighted datasets often push the algorithm toward overfitting.
Overfitting occurs when a model detects patterns that exist only inside the training dataset rather than across the broader population.
Consider a realistic scenario.
An ecommerce account produces 50 purchases in its seed list. Several of the highest-value buyers happen to share similar characteristics:
-
they browse primarily on iOS devices;
-
they engage with video ads before purchasing;
-
they convert during evening hours.
Inside the dataset, those attributes appear strongly correlated with higher purchase values.
The algorithm therefore prioritizes users who share those characteristics during lookalike expansion.
The problem is that these correlations may simply be coincidences. When the campaign begins reaching larger audiences, the predicted patterns fail to generate similar purchase behavior.
Performance declines even though the system technically followed the available data.
Delivery Instability Is a Common Warning Sign
One of the most common complaints about value-based lookalikes in small accounts is inconsistent performance.
Campaigns often begin with reasonable results and then deteriorate after a few weeks.
This pattern usually reflects unstable value signals inside the seed dataset.
Each new purchase affects the model’s weighting system. When the dataset is small, even a single high-value purchase can shift the internal ranking of signals.
Advertisers may observe several symptoms:
-
sudden spikes in cost per acquisition;
-
repeated learning phase resets;
-
inconsistent audience expansion;
-
rapidly increasing frequency within narrow segments.
The platform is continually recalibrating the value signal because it does not yet have enough data to stabilize it.
Standard lookalike audiences tend to behave more consistently because they rely only on behavioral similarity.
Diagnostic Signs That the Seed Is Too Weak
Before abandoning value-based lookalikes completely, it helps to evaluate whether the seed dataset actually supports value modeling.
Several diagnostic signals often appear when the dataset is too small.
Skewed Purchase Value Distribution
If a few orders dominate the revenue inside the seed, the model will overweight them.
This situation often appears when:
-
one or two purchases represent a large share of total revenue;
-
the average order value is much higher than the median order value;
-
occasional bulk orders appear among otherwise typical purchases.
In these cases, the value signal becomes unreliable.
Low Conversion Volume
Meta’s modeling systems typically perform best when seed audiences contain hundreds or thousands of events.
Small accounts often attempt value-based lookalikes with:
-
fewer than 100 purchases;
-
data collected over only a few weeks;
-
conversions from a single campaign source.
At that scale, the algorithm simply does not have enough examples to detect stable value patterns.
Rapid Performance Drop During Lookalike Expansion
A practical diagnostic appears when expanding the audience size.
If performance remains acceptable in a 1% lookalike audience but declines sharply at 2–5% expansion, the model’s value signal likely does not generalize well.
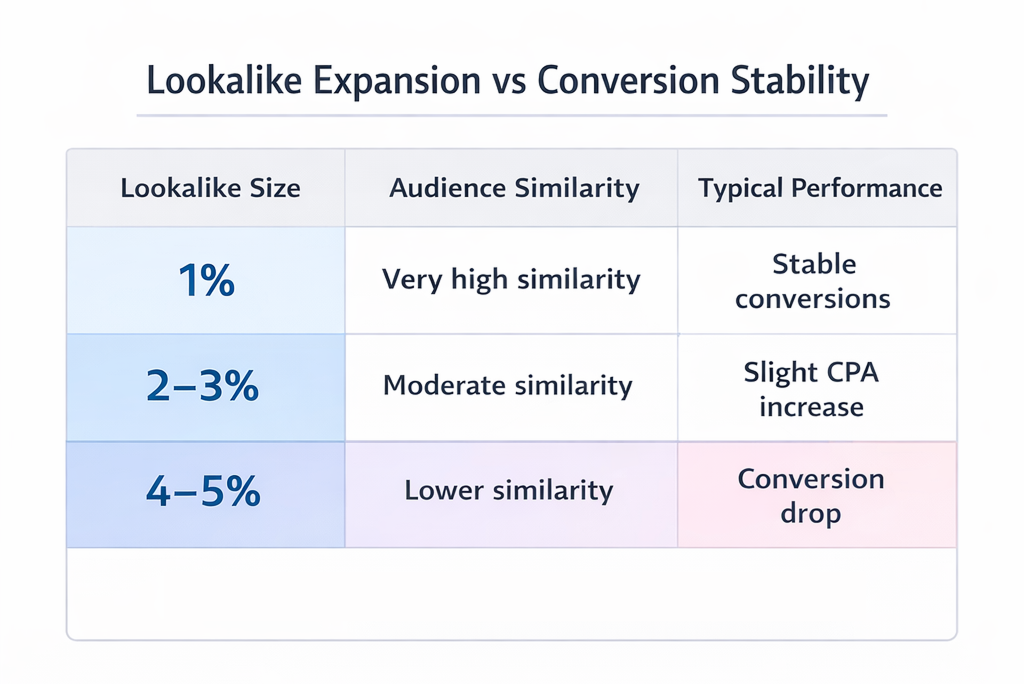
The tightest similarity band still resembles the seed users. As soon as the audience expands, the weak signal becomes visible.
What Small Accounts Should Do Instead
Rather than forcing value-based lookalikes too early, smaller advertisers usually benefit from strengthening their seed datasets first.
Several practical adjustments can improve modeling reliability.
Use Larger Seed Event Pools
Purchase events may not occur frequently enough to train the model properly.
Many advertisers improve results by using larger datasets such as:
-
add-to-cart events showing strong purchase intent;
-
initiated checkout events indicating serious buyers;
-
high-quality lead submissions from qualified prospects.
These signals occur earlier in the funnel but provide far more behavioral examples for the algorithm.
Build Separate High-Value Customer Segments
If high-value buyers represent an important segment, isolate them manually rather than relying entirely on automated value weighting.
A common approach includes:
-
exporting customers above a defined purchase threshold;
-
creating a custom audience from that segment;
-
building a standard lookalike audience from those users.
This method often produces clearer targeting signals than relying on automatic value weighting.
Expand the Data Window
Small accounts frequently build seed audiences using only recent purchases.
Extending the dataset to 90–180 days of conversions usually increases modeling stability because the algorithm receives more examples to analyze.
Advertisers building advanced targeting strategies often combine these datasets with additional audience sources. Articles like How to Build Lookalike Audiences that Actually Convert and Smarter Audience Building: Beyond Meta’s Built-In Targeting Tools explain several approaches used in more mature ad accounts.
The Strategic Takeaway
Value-based lookalike audiences depend on a strong statistical relationship between user behavior and purchase value. Small advertising accounts rarely generate enough data for that relationship to stabilize.
When the seed contains only a few dozen purchases, the algorithm often amplifies anomalies instead of identifying genuine customer patterns. This leads to narrow audiences, unstable delivery, and rising acquisition costs.
In those conditions, simpler approaches tend to work better.
Standard lookalike audiences, broader intent signals, and longer data windows usually produce stronger datasets. Once conversion volume increases and value patterns become consistent, value-based lookalikes begin to perform the way they were designed to.
