
Testing is the backbone of performance-driven marketing. But even well-structured experiments can produce false positives — results that look statistically significant but are actually driven by randomness, data leakage, or poor methodology. According to industry benchmarks, up to 30–40% of A/B test “wins” fail to replicate when re-tested, largely due to false positives. Understanding why they happen — and how to prevent them — is critical for scaling with confidence.
What Is a False Positive?
A false positive occurs when a test indicates a meaningful improvement, but the effect is not real. In statistical terms, this is a Type I error — rejecting the null hypothesis when it is actually true.
In marketing tests, false positives often show up as:
-
A sudden drop in cost per lead that disappears next week
-
One creative “winner” that underperforms when scaled
-
An audience segment that looks profitable but fails in retesting
Why False Positives Are So Common in Marketing Tests
1. Small Sample Sizes
Running tests on limited data dramatically increases noise. Research from multiple experimentation platforms shows that tests with fewer than 300–500 conversions per variant have a false-positive risk exceeding 25%.
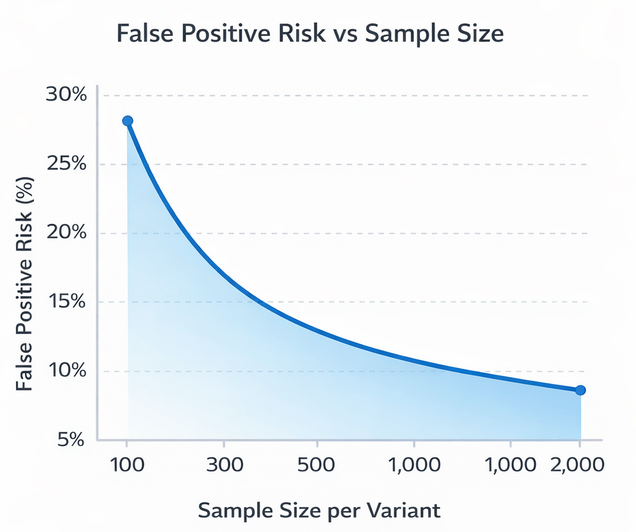
False positive risk decreases as sample size per variant increases, showing risk above 25% when samples are too small
Best practice: Define a minimum sample size before launching a test and do not stop early when results “look good.”
2. Peeking at Results Too Early
Checking results daily and stopping once significance appears inflates error rates. Studies show that repeated checking can double the probability of a false positive, even when standard significance thresholds are used.
Best practice: Commit to a fixed test duration or sample size and review results only at the end.
3. Too Many Simultaneous Tests
Testing multiple audiences, creatives, and placements at once increases the chance that at least one result will look significant by chance alone. For example, running 20 tests at a 95% confidence level statistically guarantees one false positive on average.
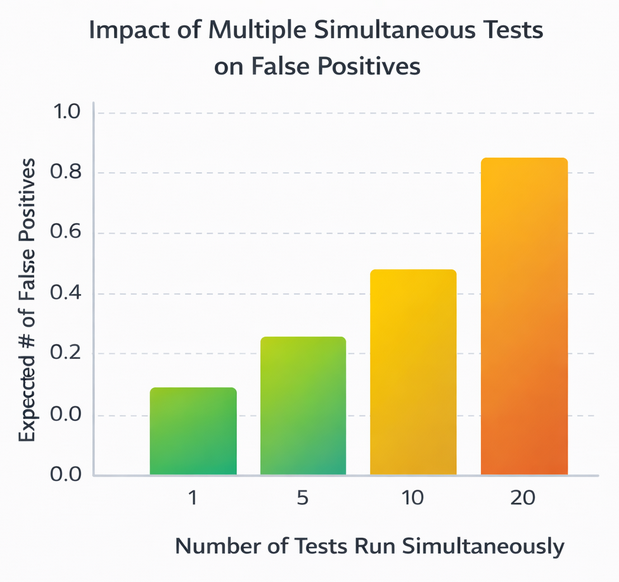
Bar chart showing how the expected number of false positives increases with the number of simultaneous tests at a 95% confidence level
Best practice: Limit parallel tests or apply stricter significance thresholds when testing many variants.
4. Poor Audience Isolation
Overlapping audiences can contaminate results. When users appear in multiple test groups, attribution becomes blurred, making one variant seem stronger than it really is.
Best practice: Ensure clean audience separation and consistent exclusion logic across tests.
How to Reduce False Positives in Practice
Use Conservative Significance Thresholds
Instead of defaulting to 95% confidence, consider 97–99% confidence for high-impact decisions. This reduces false positives at the cost of slightly longer tests — a worthwhile trade-off when scaling budgets.
Focus on Primary Metrics Only
Switching success metrics mid-test (for example, from CTR to CPL) introduces bias. Data shows that metric switching increases false-positive risk by 15–20%.
Rule: Define one primary KPI before launch and evaluate secondary metrics only after significance is reached.
Validate Wins with Retests
Top-performing teams re-run winning tests. Internal analyses from performance agencies show that retesting reduces false-positive adoption by nearly 50%.
If a result is real, it should hold under similar conditions.
Segment After, Not During
Post-test segmentation (by device, geo, or age) often reveals patterns that were never statistically powered. These insights are useful for hypotheses — not conclusions.
Best practice: Treat post-test insights as directional unless they are re-tested independently.
Key Takeaways
-
False positives are one of the biggest hidden risks in performance testing
-
Small samples, early stopping, and test overload are the main culprits
-
Stricter thresholds, disciplined test design, and retesting dramatically improve reliability
Clean testing doesn’t just prevent mistakes — it builds confidence in scaling decisions.
