
In large B2B prospect databases, data decay is inevitable. Industry research consistently shows that B2B data decays at a rate of 2–3% per month, driven by job changes, company closures, rebranding, and organizational restructuring. Over a year, that translates to roughly 22–36% of records becoming outdated.
Inaccurate data directly impacts:
-
Email deliverability and sender reputation
-
Sales productivity and connect rates
-
Marketing attribution and reporting
-
CRM forecasting reliability
-
Compliance risk and data governance
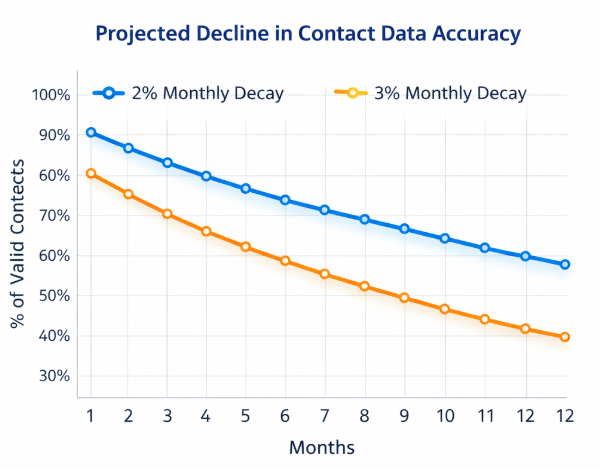
Projected decline in contact data accuracy over 12 months at 2–3% monthly decay
Even a 5% increase in bounce rate can materially reduce campaign performance, while sales teams may lose hours each week researching or correcting prospect details. At scale, this becomes a measurable revenue leak.
Common Sources of Data Inaccuracy
Large databases typically suffer from five recurring accuracy issues:
-
Contact-level decay (role changes, departures)
-
Company-level changes (mergers, rebranding, domain updates)
-
Duplicate records across systems
-
Inconsistent formatting and field standardization
-
Incomplete enrichment or missing attributes
Understanding these root causes enables targeted remediation rather than reactive cleanup.
Establishing a Data Accuracy Framework
Improving accuracy requires a structured, ongoing framework rather than periodic list cleaning.
1. Define Data Quality Metrics
Start by quantifying your current state. Core metrics should include:
-
Bounce rate percentage
-
Duplicate rate across CRM and marketing automation
-
Field completeness ratio (e.g., % of contacts with job title, company size, industry)
-
Role validity rate for target personas
-
Domain validity rate
Set acceptable thresholds. For example:
-
Bounce rate < 3%
-
Duplicate rate < 2%
-
Critical field completeness > 90%
Without benchmarks, improvement efforts remain subjective.
2. Implement Continuous Validation
Annual or quarterly cleanup is insufficient. Continuous validation processes should include:
-
Automated email verification workflows
-
Scheduled domain checks
-
Ongoing role and employment status validation
-
Real-time validation at point of data entry
This shifts data management from reactive correction to proactive maintenance.
3. Standardize Field Taxonomy
Inconsistent job titles, industries, and company sizes degrade segmentation quality. Establish:
-
Controlled vocabularies for industry classification
-
Normalized job seniority tiers
-
Consistent formatting rules for phone numbers, locations, and company names
Taxonomy normalization improves segmentation precision and reporting accuracy.
Deduplication at Scale
Duplicate records distort analytics and inflate database size. Effective deduplication requires:
-
Primary key hierarchy (email > domain + full name > domain + job title)
-
Fuzzy matching logic for near-duplicates
-
Cross-system reconciliation between CRM and marketing platforms
-
Merge rules with conflict resolution logic
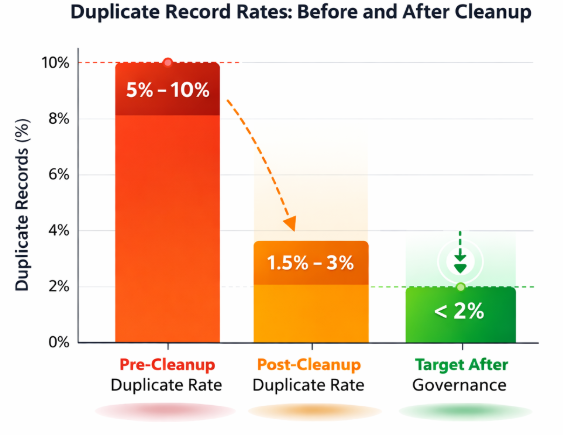
Reduction in duplicate record rates before and after implementing systematic deduplication
In enterprise environments, duplicate rates often exceed 5–10% before systematic cleanup. Reducing this to under 2% significantly improves reporting fidelity and outbound efficiency.
Enrichment and Attribute Completion
Incomplete data reduces targeting precision. High-performing teams maintain enriched profiles with:
-
Verified job titles and departments
-
Company size and revenue bands
-
Industry classification
-
Geographic region
-
Technology stack indicators (where applicable)
Attribute completeness above 90% across core segmentation fields enables more accurate ICP targeting and improves campaign ROI.
Governance and Ownership
Data accuracy deteriorates rapidly without ownership. Best practices include:
-
Assigning a data steward or revenue operations owner
-
Defining SLAs for data correction
-
Establishing intake validation rules for new records
-
Conducting quarterly data audits
Organizations with formal data governance processes consistently demonstrate higher pipeline conversion rates and more reliable forecasting.
Automation and Workflow Integration
Data quality initiatives must integrate directly into revenue workflows:
-
Validate records before outbound sequences launch
-
Trigger re-verification after inactivity thresholds
-
Automatically flag high-risk records (e.g., high bounce probability)
-
Sync updates across systems in near real time
When validation becomes embedded in operational flows, accuracy improves without adding manual overhead.
Measuring the ROI of Data Accuracy
Improving database accuracy produces measurable outcomes:
-
Increased email deliverability
-
Higher reply and connect rates
-
Reduced wasted SDR hours
-
Improved segmentation performance
-
More reliable attribution models
For example, improving contact validity from 80% to 95% in a 200,000-record database effectively restores 30,000 usable contacts. The impact on outbound capacity and pipeline generation can be substantial.
Building a Sustainable Accuracy Strategy
Long-term accuracy depends on three pillars:
-
Continuous validation processes
-
Structured governance and accountability
-
Automated enrichment and synchronization workflows
Large prospect databases are living systems. Treating them as static assets guarantees decay. Treating them as dynamic infrastructure ensures consistent performance.
Further Reading
For additional insights on optimizing prospecting operations and database performance, consider these articles:
Maintaining high data accuracy is not a one-time initiative but a continuous operational discipline. Organizations that institutionalize this discipline consistently outperform competitors in efficiency, targeting precision, and revenue predictability.
