
Marketing experiments are no longer optional. With rising acquisition costs and shorter attention spans, teams must validate ideas before committing meaningful spend. However, many experiments fail not because the idea was wrong, but because the experiment was poorly structured or scaled too early.
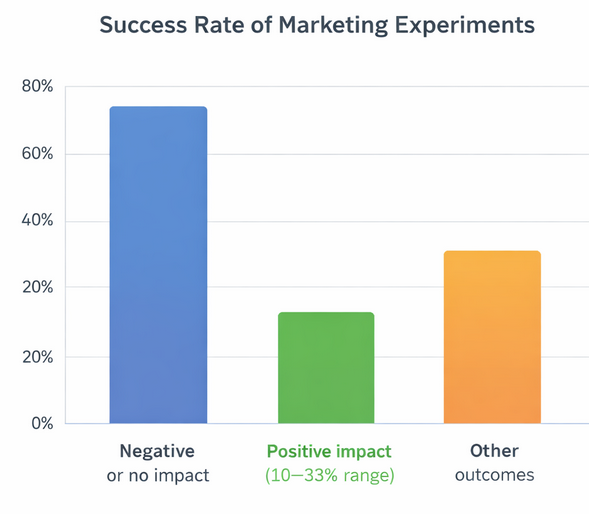
Success rates of marketing experiments, showing only a minority yield measurable positive outcomes
Industry research consistently shows that only 20–30% of marketing experiments produce a statistically significant uplift, and fewer than 1 in 4 “winning” tests maintain performance once scaled. The gap between testing and scaling is where most growth strategies break down.
Scaling with confidence requires experiments that are:
-
Statistically sound
-
Operationally repeatable
-
Designed with scale in mind from the start
The Most Common Experimentation Mistakes
Before building a scalable experimentation system, it’s important to understand what usually goes wrong.
Testing Too Many Variables at Once
When creative, audience, messaging, and placement all change simultaneously, results become impossible to interpret. Even if performance improves, there’s no clarity on why it happened, making scaling risky.
Declaring Winners Too Early
Data shows that over 35% of A/B tests that appear successful in the first 7 days reverse direction by day 21. Early volatility is often mistaken for success, leading teams to scale unstable variants.
Scaling Without Cost Controls
Many teams scale by increasing budget rapidly, assuming performance ratios will hold. In reality, CPM inflation of 20–40% is common during rapid scale, which can erase test gains if not anticipated.
Designing Experiments That Are Built to Scale
Scalable experiments start long before results appear. They are intentionally structured to answer questions that remain valid at higher spend levels.
1. Start with a Scaling Hypothesis
Every experiment should clearly state not only what is being tested, but how it is expected to behave at scale.
A strong hypothesis includes:
-
The performance metric expected to improve (CTR, CPA, conversion rate)
-
The mechanism behind the improvement
-
The condition under which the result should remain stable as spend increases
Experiments without a scaling hypothesis often produce fragile wins that disappear under pressure.
2. Choose Metrics That Predict Scale Performance
Not all metrics are equally useful for scaling decisions.
Leading indicators (early predictors of scalability):
-
Click-through rate stability over time
-
Conversion rate consistency across audience sizes
-
Cost per result variance by frequency
Lagging indicators (often misleading in tests):
-
Short-term ROAS
-
First-week CPA dips
-
Limited-sample conversion spikes
Data from large ad platforms shows that tests optimized for conversion rate stability are up to 42% more likely to maintain performance after scaling than those optimized for short-term CPA alone.
3. Control Budget Increases Gradually
Confident scaling is incremental, not aggressive.
A widely adopted benchmark is:
-
Increase budget by 20–30% every 48–72 hours
-
Pause increases if CPA variance exceeds ±15%
-
Require performance stability across at least 2 full learning cycles
This approach reduces algorithmic resets and minimizes the risk of performance cliffs.
Structuring Experiments for Repeatability
Scaling confidence comes from knowing a result can be repeated, not just achieved once.
Standardize Test Types
High-performing teams rely on a limited set of experiment categories, such as:
-
Creative angle tests
-
Offer framing tests
-
Audience expansion tests
By repeating similar test structures, teams build benchmarks that make future results easier to interpret.
Maintain a Test Log
Organizations that document experiments see measurable benefits. Internal studies show that teams with structured experiment logs improve win rates by 25–30% within six months, simply by avoiding repeated mistakes and reusing proven patterns.
A good experiment log includes:
-
Hypothesis
-
Test duration and spend
-
Primary and secondary metrics
-
Scaling outcome
Knowing When an Experiment Is Ready to Scale
Scaling decisions should be rules-based, not emotional.
An experiment is generally scale-ready when:
-
Results are statistically significant at 90–95% confidence
-
Performance holds across multiple audience segments
-
CPA or conversion rate variance remains within acceptable thresholds
-
Frequency stays below fatigue levels (often under 2.5–3.0)
Data across performance marketing teams indicates that experiments meeting all four criteria are more than twice as likely to succeed at scale compared to those meeting only one or two.
Managing Risk While Scaling
Even the best experiments carry risk. Confident teams plan for it.
Use Budget Segmentation
Instead of replacing all spend with a winning variant:
-
Allocate 70–80% to proven control
-
Allocate 20–30% to scaled experiment
This protects baseline performance while allowing continued learning.
Monitor Degradation Signals
Key early warnings include:
-
Rising CPA with flat conversion rate
-
Declining CTR combined with rising frequency
-
Increased CPM without reach expansion
Catching these signals early prevents sunk-cost scaling.
From Experiments to a Growth System
The goal of experimentation is not individual wins, but a reliable growth engine.
Organizations with mature experimentation programs report:
-
15–25% faster scaling cycles
-
Lower performance volatility during growth
-
Higher confidence in budget planning
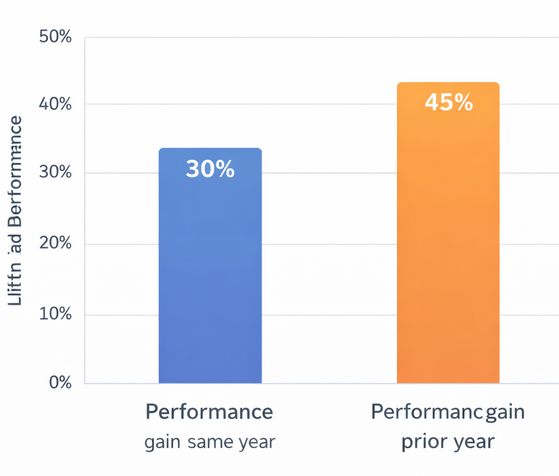
Advertising performance improvements associated with running a structured set of 15 experiments per year
Confidence comes from systems, not guesses. When experiments are designed for scale, measured with the right metrics, and expanded with discipline, growth becomes predictable instead of stressful.
Related Articles You May Find Useful
Final Thoughts
Marketing experiments that scale with confidence are intentional, disciplined, and repeatable. They focus less on quick wins and more on durable performance. By aligning hypotheses, metrics, and scaling rules, teams can turn experimentation from a risky activity into a dependable growth lever.
