
Event tracking is the backbone of modern demand generation and revenue attribution. Whether you are measuring page views, lead submissions, purchases, or custom lifecycle events, the method by which these events are captured materially affects data quality, campaign performance, and compliance posture.
Two primary models dominate today’s tracking landscape:
-
Browser (client-side) events
-
Server (server-side) events
While both approaches can technically capture similar signals, the operational trade-offs between them are significant. Selecting the wrong architecture can lead to signal loss, inflated acquisition costs, compliance risk, and flawed attribution models.
This article provides a technical and strategic comparison to guide marketing operations leaders, performance marketers, and data engineers.
What Are Browser (Client-Side) Events?
Browser events are triggered within the user’s browser using JavaScript-based tracking scripts (e.g., pixels, tags, SDKs). When a user performs an action—such as clicking a button or submitting a form—the browser transmits that event directly to third-party platforms.
Advantages of Browser Events
-
Simplicity of deployment
Client-side tracking can typically be implemented via tag managers without backend engineering support. -
Real-time activation
Events are sent instantly from the browser to ad platforms, enabling rapid optimization. -
Lower implementation cost
No additional server infrastructure is required.
Limitations of Browser Events
-
Signal loss due to ad blockers and browser restrictions
Industry estimates indicate that 30–50% of users globally employ ad blockers. Additionally, privacy-focused browsers (Safari, Firefox) and ITP-like mechanisms restrict third-party cookie lifespans to as little as 7 days. -
Dependency on third-party cookies
With third-party cookies being phased out in major browsers, client-side tracking reliability continues to degrade. -
Exposure of tracking logic
Because scripts run in the browser, tracking logic can be inspected, manipulated, or blocked. -
Data leakage and compliance complexity
Data is transmitted directly from the user’s device to multiple external vendors, complicating data governance.
What Are Server (Server-Side) Events?
Server events are generated and transmitted from a company’s backend infrastructure. Instead of the browser sending data directly to ad platforms, events are first collected by internal servers, then forwarded via secure API integrations.
Advantages of Server Events
-
Improved data durability
Server-side tracking bypasses browser restrictions and ad blockers, typically recovering 10–30% additional event signals compared to browser-only setups. -
Greater control over data processing
Organizations can standardize, enrich, hash, and validate data before distribution. -
Enhanced compliance posture
Sensitive identifiers can be pseudonymized or filtered before being transmitted externally. -
Longer attribution windows
Because server events are not constrained by short-lived browser cookies, attribution reliability improves.
Limitations of Server Events
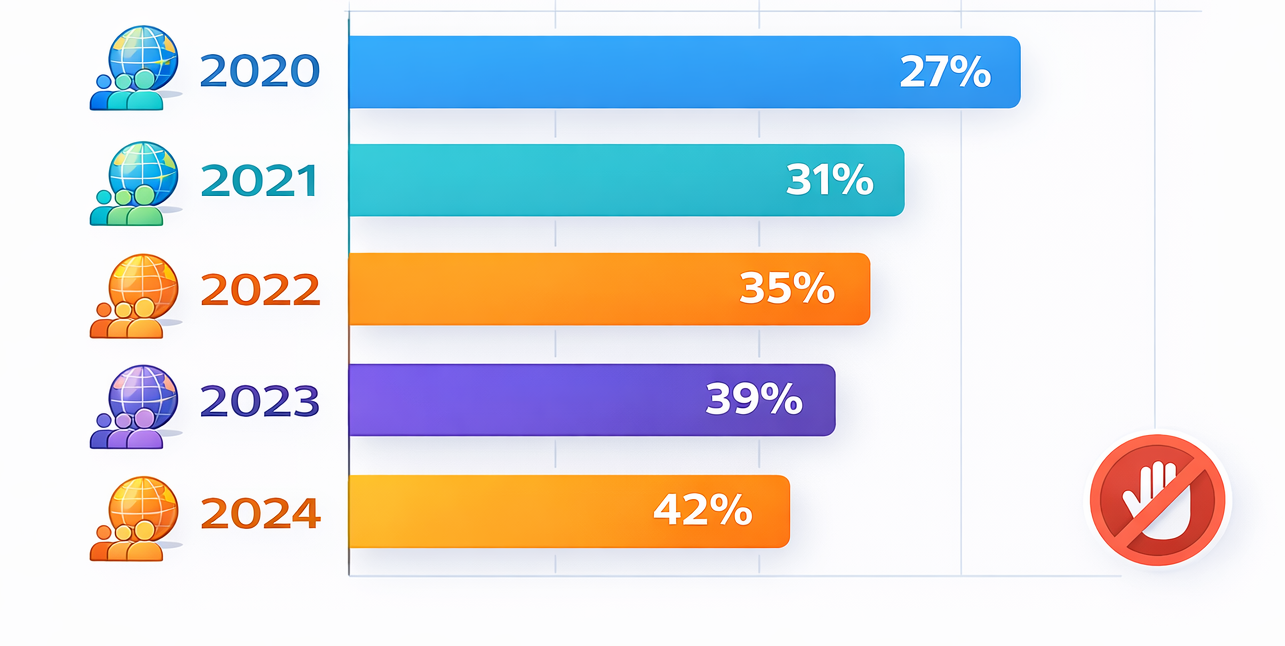
Ad blocker usage has steadily increased worldwide, with 42% of internet users blocking ads in 2024, limiting traditional browser event tracking effectiveness
-
Higher implementation complexity
Requires backend engineering, API configuration, and infrastructure oversight. -
Increased operational overhead
Monitoring, deduplication logic, and API maintenance must be managed continuously. -
Potential latency issues
If not optimized, server pipelines may introduce delays in event forwarding.
Data Accuracy and Performance Impact
Data fidelity directly affects bidding algorithms in paid media platforms. Conversion modeling systems rely on event density and match quality.
Research across multiple performance marketing studies indicates:
-
Campaigns with higher event match rates can see up to 20% lower CPA.
-
Loss of conversion signals may reduce algorithmic optimization efficiency by 15–25%.
-
Server-side augmentation commonly improves event match quality by 8–15% due to enriched identifiers.
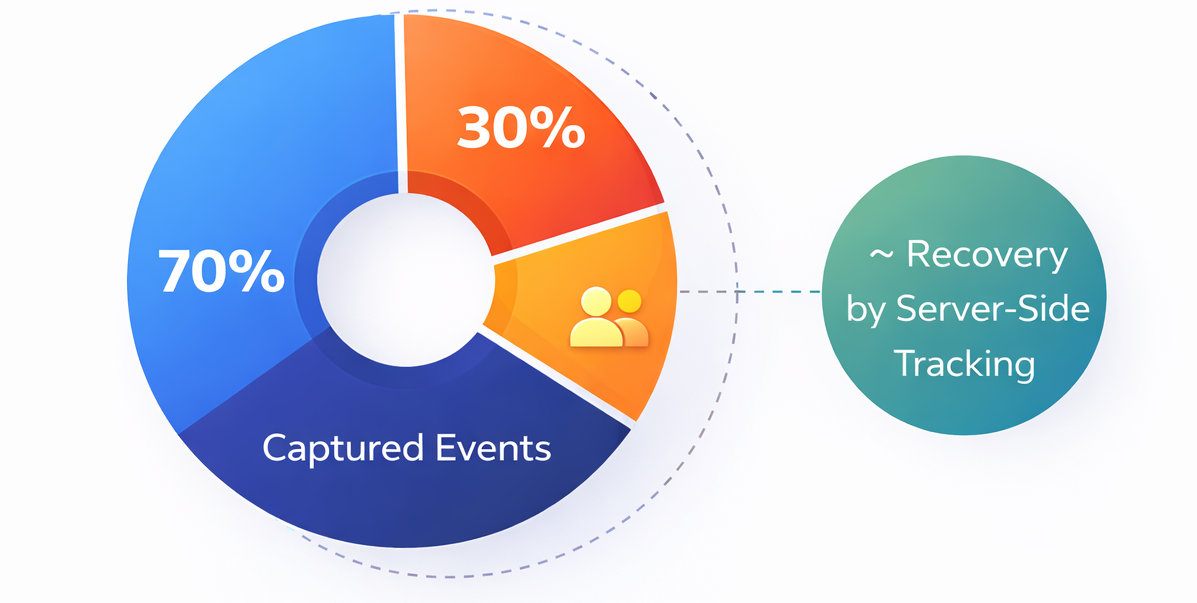
Client-side tracking can lose up to 30% of recorded events due to ad blockers and browser limitations, obscuring conversion data critical for optimization
In competitive acquisition environments, these deltas materially impact ROI.
Hybrid Architectures: The Emerging Standard
Most sophisticated organizations now implement a hybrid model:
-
Browser events for real-time behavioral triggers.
-
Server events for durable, validated conversion tracking.
Deduplication mechanisms reconcile overlapping events using unique event IDs. This architecture maximizes signal coverage while preserving optimization speed.
Hybrid models often produce the most stable attribution frameworks, especially in multi-touch B2B funnels where buying cycles exceed 30–90 days.
Compliance and Governance Considerations
Data privacy regulations (GDPR, CCPA, and similar frameworks) require demonstrable data control. Server-side architectures enable:
-
Centralized consent enforcement.
-
Standardized hashing of personally identifiable information.
-
Event filtering by geography.
Browser-only systems frequently distribute raw data directly to vendors before internal validation, increasing compliance exposure.
Strategic Decision Framework
When evaluating whether to implement browser events, server events, or both, organizations should assess:
-
Funnel complexity (short eCommerce vs. long B2B cycle).
-
Dependence on paid acquisition channels.
-
Data governance requirements.
-
Internal engineering capacity.
-
Attribution modeling sophistication.
For small teams with limited engineering resources, browser events may provide sufficient baseline tracking.
For scaling organizations investing heavily in paid acquisition and lifecycle analytics, server-side or hybrid models become strategically advantageous.
Common Implementation Pitfalls
-
Missing deduplication logic between client and server events.
-
Failing to normalize event naming conventions.
-
Not aligning marketing and engineering stakeholders.
-
Ignoring API rate limits.
-
Overlooking event validation and monitoring dashboards.
Robust QA processes and cross-functional alignment significantly reduce these risks.
Conclusion
The debate between server events and browser events is not merely technical; it is strategic. As browser privacy restrictions intensify and third-party cookies decline, reliance on client-side tracking alone introduces measurable performance and attribution risks.
Server-side tracking improves data durability, match quality, and governance control, though it requires operational maturity. In most growth-oriented environments, a hybrid model delivers the optimal balance of speed, resilience, and compliance.
Organizations that treat tracking architecture as core infrastructure rather than tactical implementation gain a durable competitive advantage in data-driven acquisition.
