
At small budgets, almost any advertising setup can look profitable. Limited spend often hides structural problems: unstable audiences, weak signals, and fragile assumptions. When budgets scale, these hidden issues surface, leading to rising costs, declining conversion rates, and inconsistent results. Understanding why test results fail to scale is the first step toward building campaigns that grow predictably.
1. Tests Rely on Fragile Audiences
During testing, campaigns often use narrow or highly specific audiences. These audiences may perform well initially but saturate quickly once spend increases. When frequency rises and fresh users become scarce, performance drops.
Key insight: A test that reaches only a small portion of an audience does not reveal how that audience behaves under sustained delivery.
Supporting statistic: Industry benchmarks show that conversion rates can drop by 30–50% once ad frequency exceeds 3.0, a common threshold reached quickly when scaling small audiences.
2. Early Results Are Statistically Misleading
Short tests often rely on limited data. A few conversions can create the illusion of strong performance, even when results are driven by randomness rather than true audience intent.
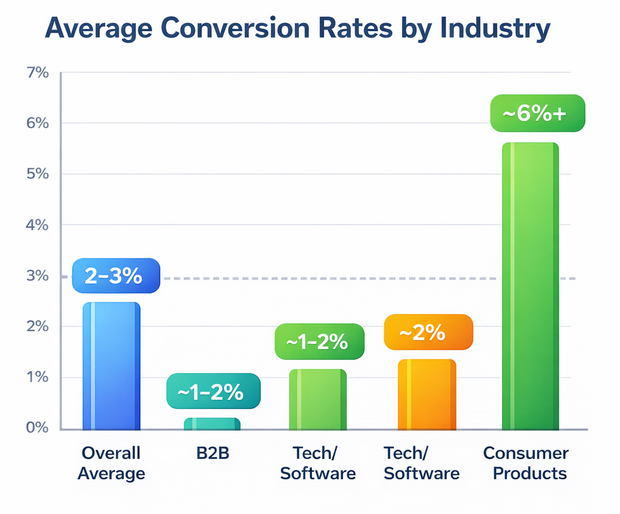
Average conversion rates vary significantly across industries, highlighting why small test results alone can misrepresent true scalable performance
Supporting statistic: Marketing analytics studies show that tests with fewer than 100 conversions can deviate from true performance by more than 25%, making early winners unreliable for scaling decisions.
What to watch for:
-
Large swings in CPA day-to-day
-
Performance concentrated in a single placement, device, or time window
-
Sudden drops once spend increases by 2–3x
3. Scaling Changes the Delivery Algorithm
When budgets increase, ad platforms adjust delivery behavior. Ads move from high-intent users to broader segments within the same audience. This shift often exposes weak targeting foundations.
Supporting statistic: Platform-level data indicates that increasing budget by more than 20–30% per day can reduce delivery efficiency by up to 15% if the audience is not large or stable enough.
Implication: A campaign that works at $20/day may be shown to a very different subset of users at $200/day.
4. Creative Fatigue Appears Faster at Scale
Testing phases often underestimate how quickly creative assets wear out. At low spend, ads may take days or weeks to reach fatigue. At scale, the same creative can peak and decline within hours.
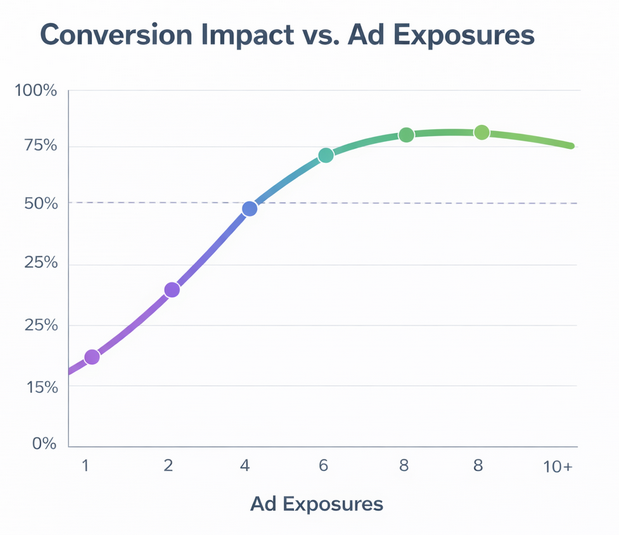
Conversion impact increases with ad frequency initially but flattens and can decline — highlighting why scaling without fresh signals often leads to performance drop-off
Supporting statistic: Performance marketers report CTR declines of 20–40% within the first 72 hours after scaling spend on a single creative.
How to Fix It: Building Tests That Scale
1. Test at Meaningful Volume
Design tests that operate closer to real scaling conditions. Instead of validating performance at minimal spend, test at a level where frequency, delivery, and creative rotation resemble future budgets.
Practical rule: If your target scaling budget is $300/day, tests at $10/day are unlikely to provide reliable signals.
2. Prioritize Audience Stability Over Precision
Highly precise audiences can outperform in tests but fail under scale. Larger, more stable audiences provide room for delivery expansion without rapid saturation.
Best practice: Favor audiences that can support at least 5–10x your test budget without exceeding healthy frequency levels.
3. Validate Across Time, Not Just Days
Short-term success does not equal long-term scalability. Run tests long enough to observe performance across different days, placements, and user segments.
Benchmark: Seven-day performance trends are significantly more predictive of scaling success than 48-hour snapshots.
4. Separate Learning Campaigns From Scaling Campaigns
Testing and scaling require different structures. Mixing both often leads to distorted data and poor optimization signals.
Approach:
-
Use testing campaigns to identify audiences and messages
-
Use separate scaling campaigns optimized for stability and efficiency
Conclusion
Test results fail to scale not because scaling is flawed, but because most tests are not designed for growth. By testing at realistic volumes, using stable audiences, collecting sufficient data, and planning for algorithmic shifts, marketers can turn fragile early wins into sustainable performance.
